SPLDS क्या हैं?
एक साधारण प्रोग्रामेबल लॉजिक डिवाइस (SPLD) एक कॉम्पैक्ट इलेक्ट्रॉनिक घटक है जिसका उपयोग इलेक्ट्रॉनिक सिस्टम में लॉजिक फ़ंक्शन करने के लिए किया जाता है।यह अपनी सीधी संरचना और शक्ति के बिना भी कॉन्फ़िगरेशन को बनाए रखने की क्षमता के लिए जाना जाता है।इस लेख में, आप SPLD के बारे में जानेंगे, इसकी तुलना अन्य उपकरणों, इसकी विशेषताओं और इसके मॉडल कैसे काम करती है।सूची

SPLD का परिचय
एक साधारण प्रोग्रामेबल लॉजिक डिवाइस (SPLD) एक प्रकार का एकीकृत सर्किट है जिसे विभिन्न प्रकार के लॉजिक ऑपरेशंस को पूरा करने के लिए डिज़ाइन किया गया है।एक जटिल PLD (CPLD) के समान, एक SPLD आमतौर पर कम इनपुट/आउटपुट पिन और प्रोग्रामेबल तत्वों के साथ आता है।यह इसे अधिक शक्ति-कुशल और संरचना में सरल बनाता है।
SPLD को कॉन्फ़िगर करने के लिए, आपको अक्सर एक विशिष्ट प्रोग्रामिंग डिवाइस की आवश्यकता होती है।निर्माताओं के पास इन उपकरणों की प्रोग्रामिंग के लिए अपने अनूठे तरीके हो सकते हैं, इसलिए प्रक्रिया अलग -अलग हो सकती है।इसके बावजूद, SPLDs की एक सामान्य विशेषता यह है कि वे गैर-वाष्पशील हैं।इसका मतलब है कि वे बिजली बंद होने पर भी अपने कॉन्फ़िगरेशन को बरकरार रख सकते हैं।
एक SPLD के अंदर, आपको प्रोग्रामेबल लॉजिक गेट्स और पॉइंट्स का एक संग्रह मिलेगा, जो इसे विभिन्न कार्यों को करने में सक्षम बनाता है।कई SPLDs में मेमोरी तत्व और फ्लिप-फ्लॉप भी शामिल हैं, जो तर्क और मेमोरी-आधारित दोनों डिजाइन बनाने में उनकी बहुमुखी प्रतिभा को जोड़ते हैं।
अन्य PLDs के साथ SPLD की तुलना
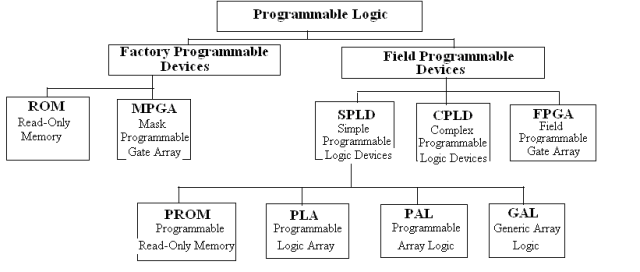
प्रोग्रामेबल लॉजिक डिवाइस (पीएलडी) एक व्यापक श्रेणी है जिसमें कई प्रकार के डिवाइस शामिल हैं जैसे कि प्रोग्रामेबल रीड-ओनली मेमोरी (PROM), इरेज़ेबल प्रोग्रामेबल रीड-ओनली मेमोरी (EPROM), प्रोग्रामेबल लॉजिक एरे (PLA), प्रोग्रामेबल एरे लॉजिक (PAL), और जेनेरिक सरणी तर्क (GAL)।प्रत्येक प्रकार को अद्वितीय संरचनात्मक सुविधाओं और कार्यों के साथ डिज़ाइन किया गया है, जैसा कि नीचे दी गई तालिका में संक्षेप में प्रस्तुत किया गया है।
पीएलए की संरचना एक प्रोम के साथ समानताएं साझा करती है।दोनों में और गेट्स, या गेट्स, और आउटपुट बफ़र्स की एक व्यवस्था है।हालांकि, एक पीएलए में गेट सरणी प्रोग्राम करने योग्य है, अधिक लचीलापन प्रदान करता है।एक ही तर्क कार्यों का निर्माण करते समय, PLA आमतौर पर प्रोम्स की तुलना में और या गेट सरणियों में कम कोशिकाओं का उपयोग करते हैं, जिससे वे कुछ अनुप्रयोगों के लिए अधिक कुशल होते हैं।
दूसरी ओर, पाल उपकरणों में कभी -कभी एक पंजीकृत आउटपुट संरचना शामिल होती है।यह उन्हें संयोजन और अनुक्रमिक तर्क कार्यों दोनों को संभालने की अनुमति देता है, जो उन्हें डिजाइन की एक विस्तृत श्रृंखला के लिए उपयुक्त बनाता है।GAL डिवाइस बहुमुखी प्रतिभा को अपने प्रोग्रामेबल मैक्रो-लॉजिक इकाइयों के साथ एक कदम आगे ले जाते हैं, जो विभिन्न परिचालन मोड प्रदान करते हैं।ये मोड पाल उपकरणों में पाए जाने वाले विभिन्न आउटपुट संरचनाओं को दोहरा सकते हैं।
जबकि PAL और GAL डिवाइस समर्पित टूल और प्रोग्रामिंग भाषाओं की आवश्यकता के कारण जटिल हो सकते हैं, इन उपकरणों को उपयोगकर्ता के अनुकूल होने के लिए डिज़ाइन किया गया है।यह पाल और गैल उपकरणों के साथ काम करना, उनकी उन्नत क्षमताओं के साथ भी सुलभ है।
Atmel SPLD का अवलोकन
Atmel SPLD उत्पाद, जैसे कि 16V8 और 22V10, उद्योग मानकों को पूरा करने के लिए डिज़ाइन किए गए हैं और विभिन्न बिजली और वोल्टेज आवश्यकताओं के लिए कई विकल्पों की पेशकश करते हैं।इनमें कम-वोल्टेज, शून्य-शक्ति और क्वार्टर-पावर संस्करण शामिल हैं, जो विभिन्न प्रकार की जरूरतों के लिए खानपान हैं।Atmel "L" श्रृंखला उपकरण भी प्रदान करता है, जिसमें स्वचालित पावर-डाउन कार्यक्षमता होती है, जिससे वे अत्यधिक ऊर्जा-कुशल बनते हैं।एक लोकप्रिय उदाहरण ATF22LV10CQZ, एक बैटरी-अनुकूल विकल्प है।
Atmel SPLDS एक मालिकाना TSSOP पैकेज में उपलब्ध हैं, जो SPLD उपकरणों के लिए सबसे छोटे डिजाइनों में से एक है।वे विभिन्न प्रणालियों के साथ संगतता सुनिश्चित करते हुए अन्य सामान्यतः उपयोग किए जाने वाले पैकेजिंग प्रारूपों का भी समर्थन करते हैं।सभी Atmel SPLD उत्पादों को EE तकनीक का उपयोग करके बनाया गया है, जो विश्वसनीय प्रदर्शन और दोहराने योग्य प्रोग्रामिंग सुनिश्चित करता है।इसके अतिरिक्त, वे व्यापक रूप से उपलब्ध तृतीय-पक्ष प्रोग्रामिंग टूल द्वारा समर्थित हैं, जिससे उन्हें काम करना आसान हो जाता है।
SPLD मॉडल को समझना
SPLD मॉडल को यह सुनिश्चित करके नमूनों के भीतर विविधता पर ध्यान केंद्रित करने के लिए डिज़ाइन किया गया है कि चयनित नमूने यथासंभव विविध हैं।यह विविधता इस विचार पर आधारित है कि एक ही समूह या क्लस्टर के भीतर नमूने विभिन्न समूहों के लोगों की तुलना में एक दूसरे के समान होते हैं।यह क्लस्टरिंग दृष्टिकोण डेटा में व्यवहार और पैटर्न की एक विस्तृत श्रृंखला को पकड़ने में मदद करता है।
उदाहरण के लिए, एक वीडियो मान्यता कार्य में, एक ही वीडियो के फ्रेम को उनकी समानता के कारण उसी क्लस्टर का हिस्सा माना जाता है।दूसरी ओर, विभिन्न वीडियो के फ्रेम विविधता का प्रदर्शन करते हैं क्योंकि वे अलग -अलग समूहों से संबंधित हैं।यह अवधारणा SPLD पर लागू होती है, जहां डेटा सेट को समूहों में विभाजित किया जाता है, और सिस्टम इन समूहों के भीतर उनकी विविधता के आधार पर नमूनों को मान प्रदान करता है।
मॉडल एक पैरामीटर मैट्रिक्स का परिचय देता है जो कई समूहों में सीखने के वजन को वितरित करता है।यह सुनिश्चित करता है कि चयनित नमूने एक क्लस्टर में केंद्रित होने के बजाय डेटा के एक व्यापक स्पेक्ट्रम को कवर करते हैं।यह SPLDS को सादगी (आसान नमूनों के लिए वजन असाइन करना) और विविधता (कई समूहों से चुनना) के बीच संतुलन बनाने की अनुमति देता है।
SPLD की एक अनूठी विशेषता एक उद्देश्य फ़ंक्शन का उपयोग है जो नकारात्मक L2,1 मानदंड नामक विधि के माध्यम से विविधता को बढ़ावा देती है।पारंपरिक एसपीएल के विपरीत जो कुछ समूहों पर ध्यान केंद्रित कर सकते हैं, एसपीएलडी यथासंभव कई समूहों में नमूना चयन फैलाने को प्रोत्साहित करता है।यह अतिरेक से बचकर एक समृद्ध सीखने का अनुभव बनाता है।
SPLD अनुकूलन एक चरण-दर-चरण दृष्टिकोण का अनुसरण करता है, जो मापदंडों के दो सेटों को अपडेट करने के बीच बारी-बारी से है।उनके नुकसान मूल्यों के आधार पर नमूनों को रैंकिंग करके और धीरे -धीरे घटती सीमा को लागू करने के लिए, SPLD यह सुनिश्चित करता है कि इसमें नमूनों का मिश्रण शामिल है, जिसमें सरल से अधिक जटिल तक शामिल हैं।यह प्रक्रिया एक विविध और संतुलित चयन सुनिश्चित करती है, जो पारंपरिक एसपीएल विधियों से अलग SPLD को सेट करती है।
SPLD में अनुकूलन प्रक्रिया
SPLD में अनुकूलन प्रक्रिया इस बात पर ध्यान केंद्रित करती है कि नमूनों को कैसे चुना जाता है और क्लस्टर में वितरित किया जाता है।इसका उद्देश्य एक गैर-उत्तल अनुकूलन समस्या को हल करके विविधता और सीखने की प्रभावशीलता को संतुलित करना है।यह एक उद्देश्य फ़ंक्शन के माध्यम से प्राप्त किया जाता है:
यहाँ:
फ़ंक्शन को दो मापदंडों का उपयोग करके विविध नमूना चयन को प्रोत्साहित करते हुए नुकसान को कम करने के लिए डिज़ाइन किया गया है, और ।ये सरल नमूनों पर ध्यान केंद्रित करने और विविधता सुनिश्चित करने के बीच संतुलन को नियंत्रित करते हैं।
चूंकि डेटा को अक्सर समूहों में वर्गीकृत किया जाता है, इसलिए अनुकूलन समस्या को छोटे उप-समस्याओं में तोड़ दिया जाता है।प्रत्येक क्लस्टर इसका अपना अनुकूलन कार्य है:
यहाँ, के लिए नुकसान का प्रतिनिधित्व करता है क्लस्टर में -th नमूना ।समाधान यह सुनिश्चित करता है कि प्रत्येक क्लस्टर समग्र सीखने की प्रक्रिया में नमूनों के विविध सेट का योगदान देता है।
चयन प्रक्रिया को और परिष्कृत करने के लिए, नमूने उनके नुकसान के आधार पर रैंक किए जाते हैं।एक दहलीज, मापदंडों द्वारा निर्धारित किया गया और , गतिशील रूप से समायोजित करता है क्योंकि अधिक नमूने चुने जाते हैं:
यदि किसी नमूने का नुकसान संतुष्ट करता है , यह चयनित है ();अन्यथा, यह नहीं है ()।
अनुकूलन अद्यतन करने के बीच वैकल्पिक है और , यह सुनिश्चित करना कि प्रत्येक चरण बेहतर परिणाम प्राप्त करने के लिए मापदंडों को परिष्कृत करता है।घटती सीमा को शामिल करके, SPLD में समय के साथ उच्च नुकसान के साथ नमूने शामिल हैं, जो सरल और अधिक चुनौतीपूर्ण उदाहरणों का मिश्रण सुनिश्चित करते हैं।यह विधि नमूना विविधता को बनाए रखते हुए सीखने की दक्षता में सुधार करती है।
यह संरचित दृष्टिकोण, सटीक गणितीय परिभाषाओं के साथ मिलकर, SPLD को जटिल, विषम डेटा परिदृश्यों के लिए प्रभावी बनाता है।
हमारे बारे में
ALLELCO LIMITED
और पढो
त्वरित पूछताछ
कृपया एक जांच भेजें, हम तुरंत जवाब देंगे।

SRAM क्या है?
2025/01/14 पर

ADM699AR एनालॉग डिवाइस विकल्प, सुविधाएँ, अनुप्रयोग
2025/01/14 पर
लोकप्रिय लेख
-

कॉम्प्लेक्स इंस्ट्रक्शन सेट कंप्यूटर: उन्होंने कंप्यूटिंग को कैसे बदला?
8000/04/18 पर 147758
-

यूएसबी-सी पिनआउट और सुविधाएँ
2000/04/18 पर 111942
-

Xilinx यूनिफाइड सिमुलेशन प्राइमिटिव्स का उपयोग करना: FPGA डिजाइन और सिमुलेशन के लिए एक व्यापक गाइड
1600/04/18 पर 111349
-

इलेक्ट्रॉनिक्स में विद्युत आपूर्ति वोल्टेज: वीसीसी, वीडीडी, वीईई, वीएसएस और जीएनडी का अर्थ
0400/04/18 पर 83721
-

RJ45 कनेक्टर गाइड: पिनआउट, वायरिंग, केबल प्रकार, और उपयोग
1970/01/1 पर 79508
-

आधुनिक विद्युत प्रणालियों में वायर रंग कोड के लिए अंतिम गाइड
जिस तरह से हमारे इलेक्ट्रिकल सिस्टम रंगों का उपयोग करते हैं, वह केवल लुक के लिए नहीं है।प्रत्येक तार का रंग अब एक विशिष्ट फ़ंक्शन को इंगित करता है, जिससे स्थापना और रखरखाव के दौरान विद्युत घटकों को...1970/01/1 पर 66915
-

पर्ज वाल्व गाइड: इष्टतम इंजन प्रदर्शन के लिए फ़ंक्शन, लक्षण, परीक्षण और प्रतिस्थापन
पर्ज वाल्व एक कार की प्रणाली का एक महत्वपूर्ण हिस्सा है जो वायुमंडल में भागने से पहले ईंधन वाष्प को प्रबंधित करके हवा को साफ रखने में मदद करता है।यह न केवल प्रदूषण को कम करके पर्यावरण में मदद करता ...1970/01/1 पर 63065
-

गुणवत्ता (क्यू) कारक: समीकरण और अनुप्रयोग
गुणवत्ता कारक, या 'क्यू', यह जाँच करते समय महत्वपूर्ण है कि रेडियो आवृत्तियों (आरएफ) का उपयोग करने वाले इलेक्ट्रॉनिक सिस्टम में कितनी अच्छी तरह से इंडक्टर्स और रेज़ोनेटर काम करते हैं।'क्यू' मापता ह...1970/01/1 पर 63012
-

अधिकतम बिजली हस्तांतरण प्रमेय के साथ शिखर प्रदर्शन प्राप्त करना
अधिकतम पावर ट्रांसफर प्रमेय बताता है कि कैसे एक स्रोत से ऊर्जा, जैसे कि बैटरी या जनरेटर, एक जुड़े लोड में बहती है।यह सटीक स्थिति दिखाता है जहां लोड सबसे अधिक शक्ति प्राप्त करता है।इस लेख में शामिल ...1970/01/1 पर 54081
-

A23 बैटरी विनिर्देशों और संगतता
A23 बैटरी उच्च वोल्टेज के साथ एक छोटी, सिलेंडर के आकार की बैटरी है।जिसे 23A, 23AE, या MN21 भी कहा जाता है, यह 12 वोल्ट पर चलता है और AA या AAA बैटरी की तुलना में बहुत अधिक है।इसका विशेष डि...1970/01/1 पर 52138
हॉट पार्ट नंबर
-

BD4743G-TR
Rohm Semiconductor
IC SUPERVISOR 1 CHANNEL 5SSOP
HCPL-0314-560E
Broadcom Limited
OPTOISO 3.75KV 1CH GATE DRVR 8SO
IDT49FCT805CTSO
Renesas Electronics America Inc
IC CLK BUFFER 1:5 20SOIC
S912XHZ512F1VAL
Freescale Semiconductor
IC MCU 16BIT 512KB FLASH 112LQFP
XC3S250E-5TQG144C
AMD
IC FPGA 108 I/O 144TQFP
MX7824KCWG+
Analog Devices Inc./Maxim Integrated
IC ADC 8BIT FLASH 24SOIC
NBC12439FA
onsemi
IC PLL CLOCK GENERATOR 32LQFP
VHF15-08IO5
IXYS
RECT BRIDGE 1PH 800V PWS-E-1
MIC4468YWM
Microchip Technology
IC GATE DRVR LOW-SIDE 16SOIC
CL10A105KP8NNNL
Samsung Electro-Mechanics
CAP CER 1UF 10V X5R 0603
LC4032ZC-75MN56C
Lattice Semiconductor Corporation
IC CPLD 32MC 7.5NS 56CSBGA
2SK1589-T1B-A
Renesas Electronics America Inc
SMALL SIGNAL N-CHANNEL MOSFET
N79E825ADG
Nuvoton Technology Corporation
IC MCU 8BIT 16KB FLASH 20DIP
18125E684MAT2A
KYOCERA AVX
CAP CER 0.68UF 50V Z5U 1812
MMA6823AKGCWR2
NXP USA Inc.
ACCELEROMETER 50G SPI 16QFN
S115FP
onsemi
DIODE SCHOTTKY 150V 1A SOD123HE
MAX4489AUA+
Analog Devices Inc./Maxim Integrated
IC OPAMP GP 2 CIRCUIT 8UMAX
LPS25HBTR
STMicroelectronics
SENSOR 18.27PSIA 24BIT 10LLGA -

0805J0500103KXT
Knowles Syfer
CAP CER 10000PF 50V X7R 0805
74HCT4051D,118
Nexperia USA Inc.
IC MUX 8:1 120OHM 16SO
CDSOT23-T36C
Bourns Inc.
TVS DIODE 36VWM 76.8VC SOT23-3
MSTC90-16
Microsemi Corporation
MOD THYRISTOR DIODE 90A SF1
MB90F362TESPMT-GSE1
Infineon Technologies
IC MCU 16BIT 64KB FLASH 48LQFP
101X18W104MV4E
Johanson Dielectrics, Inc.
CAP CER 0.1UF 100V X7R 1206
VI-26P-CV
Vicor Corporation
DC DC CONVERTER 13.8V 150W
HSP50415VIZ
Renesas Electronics America Inc
IC MODULATOR PROGRAMABLE 100MQFP
R5F100FEAFP#X0
Renesas Electronics America Inc
IC MCU 16BIT 64KB FLASH 44LQFP
STM8AF6246UCY
STMicroelectronics
IC MCU 8BIT 16KB FLASH 32VFQFPN
JANS2N2369AUB
Microchip Technology
TRANS NPN 20V UB
BD678A
STMicroelectronics
TRANS PNP DARL 60V 4A SOT32-3
HUF76429D3ST
onsemi
MOSFET N-CH 60V 20A TO252AA
MC79M15BDTRKG
onsemi
IC REG LINEAR -15V 500MA DPAK
LNBH29EPTR
STMicroelectronics
IC LNB CTRL STEP-UP I2C
ATMEGA8515-16AU
Atmel
IC MCU 8BIT 8KB FLASH 44TQFP
TMK212ABJ225MD-T
Taiyo Yuden
CAP CER 2.2UF 25V X5R 0805
STB13N60M2
STMicroelectronics
MOSFET N-CH 600V 11A D2PAK -

SMF22A-E3-08
Vishay General Semiconductor - Diodes Division
TVS DIODE 22VWM 35.5VC SMF
17-21UYC/S530-A3/TR8
Everlight Electronics Co Ltd
LED YELLOW CLEAR SMD
06032U1R9CAT2A
KYOCERA AVX
CAP CER 1.9PF 200V NP0 0603
MIC2179-3.3BSM
Microchip Technology
IC REG BUCK 3.3V 1.5A 20SSOP
C1005X5R0J475K050BC
TDK Corporation
CAP CER 4.7UF 6.3V X5R 0402
06035A110CAT2A
KYOCERA AVX
CAP CER 11PF 50V NP0 0603
SBR30150CTFP-G
Diodes Incorporated
DIODE ARRAY SBR 150V 15A ITO220
CC0805KRX7R9BB273
YAGEO
CAP CER 0.027UF 50V X7R 0805
FQA90N15
onsemi
MOSFET N-CH 150V 90A TO3PN
71918-126LF
Amphenol ICC (FCI)
CONN HEADER VERT 26POS 2.54MM
PTN78020WAZ
Texas Instruments
DC DC CONVERTER 2.5-12.6V
PIC16F688-I/ST
Microchip Technology
IC MCU 8BIT 7KB FLASH 14TSSOP
PI3EQX12904AZHEX
Diodes Incorporated
PCIE EQX V-QFN3590-42
FCP099N60E
Fairchild Semiconductor
MOSFET N-CH 600V 37A TO220-3
OPA2320AIDR
Texas Instruments
IC CMOS 2 CIRCUIT 8SOIC
GRM31M6T2A121JD01L
Murata Electronics
CAP CER 120PF 100V T2H 1206
FOD852S
onsemi
OPTOISOLATOR 5KV DARLINGTON 4SMD
XTR105UA
Texas Instruments
IC CURRENT TRANSMITTER 14SOIC